 BSI C5 testiert • DSGVO & GoBD konform
BSI C5 testiert • DSGVO & GoBD konform
 30 Tage unverbindlich testen
30 Tage unverbindlich testen
Schnelle Recherche in Dateien
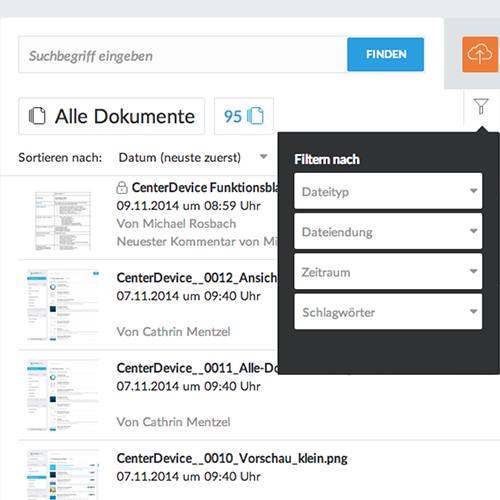
Ein Cloudspeicher-Dienst mit ausgereifter Suchfunktion erleichtert die Dokumentenorganisation extrem, gerade für die berufliche Nutzung ist eine zuverlässige Suche ein Entscheidungskriterium. Wenn der Nutzer Wichtiges schnell findet, basiert dies auf innovativer Technologie. Wir bei CenterDevice setzen auf eine ordnerlose Logik, und verwenden moderne Mechanismen für die „Suchmaschine für Unternehmensdateien“.
Dr. Patrick Peschlow, Entwicklungsleiter bei CenterDevice, lässt uns in die Funktionsweise der CenterDevice-Suche blicken:

„CenterDevice extrahiert Text, abhängig von der Dokumentenart, über direkte Textextraktion oder OCR. Apache Tika nutzen wir zur direkten Textextraktion, es kann verschiedene Dateitypen lesen und extrahiert deren Text. Das Ergebnis ist in der Regel perfekt, denn die Dokumente liefern den Text ja bereits „lesbar“ mit.
OCR ist die zweite Variante: Wir nutzen Tesseract zur Texterkennung von Dateien, die den Text nicht mitliefern. Dazu werden Bildformate verwendet, in denen die OCR nach bestimmten Regeln Zeichen und Worte bestmöglich erkennt. Eine OCR ist in der Regel fehlerbehaftet und muss deshalb auf verschiedene Schrifttypen und -größen etc. „trainiert“ werden. Idealerweise werden auch die Bildformate vorverarbeitet (so erfolgt z.B. eine Konvertierung des Bildes nach Schwarz-Weiß).
CenterDevice speichert in den meisten Fällen eines der beiden Ergebnisse zu einem Dokument als Volltext ab (bevorzugt ist dies der mit Tika extrahierte Text).
Sollte Tika im Einzelfall wenig Text geliefert haben, die OCR dafür viel mehr, werden beide Ergebnisse abgespeichert. Oft liegt dann ein gescanntes Dokument vor (dessen Text die OCR extrahiert), das mit einem programmatischen Stempel (dessen Text Tika findet) versehen wurde.
Volltextsuche via Index
Im Suchindex wird das Ergebnis für jedes Dokument abgelegt. Über die Volltextsuche ist es dort in der Anwendung verfügbar. Die Suche arbeitet unter anderem mit Wortstämmen, so muss man bei Suchbegriffen nicht auf Groß-/Kleinschreibung oder Singular/Plural achten.
Beispiel: Steht im Dokument „Rechnungen“, findet man es mit dem Suchbegriff „rechnung“. Auch Präfixsuche wird bis zu einer bestimmten Präfixlänge unterstützt: Mit „rechn“ findet man z.B. alle Dokumente, in denen „Rechnung“, „Rechnungen“, „Rechnungsnummer“, „Rechner“, etc. steht.
Schließlich ist bis zu einem gewissen Grad auch das Auffinden von Dokumenten über Teilworte möglich – z.B. Abschnitte zwischen Trennzeichen (Bindestriche, Unterstriche) oder Teilworte von Worten in CamelCase. Das gilt jedoch nicht für beliebige Buchstabenfolgen weil dies nicht effizient realisiert werden kann.
Indizierung von Metadaten
Neben dem Volltext indizieren wir diverse Metadaten eines Dokuments: Dateiname, Metadaten wie Autor oder Titel (falls bekannt), vergebene Schlagworte sowie Namen und E-Mail-Adressen von Personen, die mit dem Dokument zu tun haben (Eigentümer, Uploader, direkte Freigaben). In diesen Feldern wird – ähnlich wie im Volltext – gesucht, es gibt aber Unterschiede in den Details. Nur ein Beispiel: Bei den Dateinamen werden deutlich längere Präfixe unterstützt, da Benutzer oft auf diese Weise nach Dateinamen suchen.
Die Treffer einer Dokumenten-Suche werden sortiert nach Relevanz zurückgeliefert. Intuitiv bedeutet „Relevanz“, dass Dokumente höher bewertet werden wenn sie die Suchbegriffe „besser“ matchen (wenn z.B. die Suchbegriffe besonders oft darin vorkommen, oder die Suchbegriffe gleich in mehreren Feldern eines Dokuments – z.B. Volltext, Dateiname und Titel – gefunden werden).
CenterDevice bewertet außerdem manche Felder höher als andere. Die aktuelle Gewichtung ist: Dateiname, Eigentümer, Uploader, direkte Freigaben, Schlagworte, Titel, Autor, Volltext.
Das mag überraschen, denn der Volltext hat die niedrigste Gewichtung. Sucht man nun nach „rechnung“ und viele Dokumente haben dieses Schlagwort, werden sie in der Suche alle vor Dokumenten erscheinen, denen das Schlagwort fehlt, die aber „Rechnung“ im Text enthalten.
Filtern mit Elasticsearch
Zusätzlich zur Suche bieten wir diverse Filter (Facetten) an, mit denen man gezielt die Suchmenge einschränken kann, z.B. über die Dateiendung. Auch kann man im Kontext einer Sammlung suchen und erhält nur Treffer aus der ausgewählten Sammlung.
Im Webclient bietet CenterDevice zusätzlich Suchvorschläge an, sobald der Benutzer ins Suchfeld tippt, z.B. Schlagworte oder Benutzernamen.
Durch die interne Verwendung der Suchlösung Elasticsearch garantiert CenterDevice, dass die Suche auch über große Datenmengen skalierbar ist.“